My dissertation project looks at the white supremacist movement in the United States and Canada. I am principally interested in how white supremacist organizations attempt to recruit, impression manage, and convince their members to conduct high risk/cost activism. Using a large dataset of over 2 million messages from white supremacists on Discord, leaked online by media outlet Unicron Riot, I am able to get a “behind closed doors” look at various of these organizations. This project primarily uses qualtiative methods but also relies on some computational and natural language processing techniques, some of which are visualized below.
The first article of my dissertation looks at how white supremacist organizations try to convince the anonymous individual users that form part of their chat servers to become commited to the white power movement and engage in higher risk forms of activism. Because of the high-risks involved with engaging in white power activism, organizations need to come up with various strategies to convince newcomers to the movement to engage in dangerous actions. I find that white supremacist organizations create strong motivational frames, collective identities and sense of efficacy, as well as the use of negative/psotiive sanctions and a bevy of ways to mitigate both the risks and the costs of white supremacist activism.
The second article of my dissertation examines how external political changes, in particular, a contentious presidential election, and growing power devaluation in key aspects of a communities life (economic, cultural and political) can have a profound impact on the emergence of extremist movements.
The final empirical chapter of my dissertation, published in Research in Social Movements, Conflicts and Change looks at how white supremacist groups attempt to cater their public images in ways which will make them more acceptable to the broader American public. Like other social movement organizations, white supremacist groups want to gain public support, however, they belong to a heavily reviled and stigmatized movement. Because of this, these groups choose several and at times differing strategies to make their beliefs, organizations and actions more palatable to the public. In fact, almost all aspects of the organizations were carefully selected and debated, and need to conform with what they call “optics”. This chapter uses several concepts from Goffmanian sociology and applies them to social movements studies, specifically: impression management, frontstage/backstage and stigma.
The Dataset
Everything below is a work in progress and contains some descriptive statistics on the data used and will be periodically updated as I continue to work on this website.
In total, my dataset contains 7519 unique users and 1936692 unique messages from 22 “organizations”. There are a total of 33 servers in my dataset, though some of these servers belong to the same organization. Though it was difficult to get demographic data from users in the chats, the average age for users was 22 years old. Only 0.2% of users identified as openly non-white. the rest I presume were white. Only 80 users identified as women, one of which identified as Transgendered.
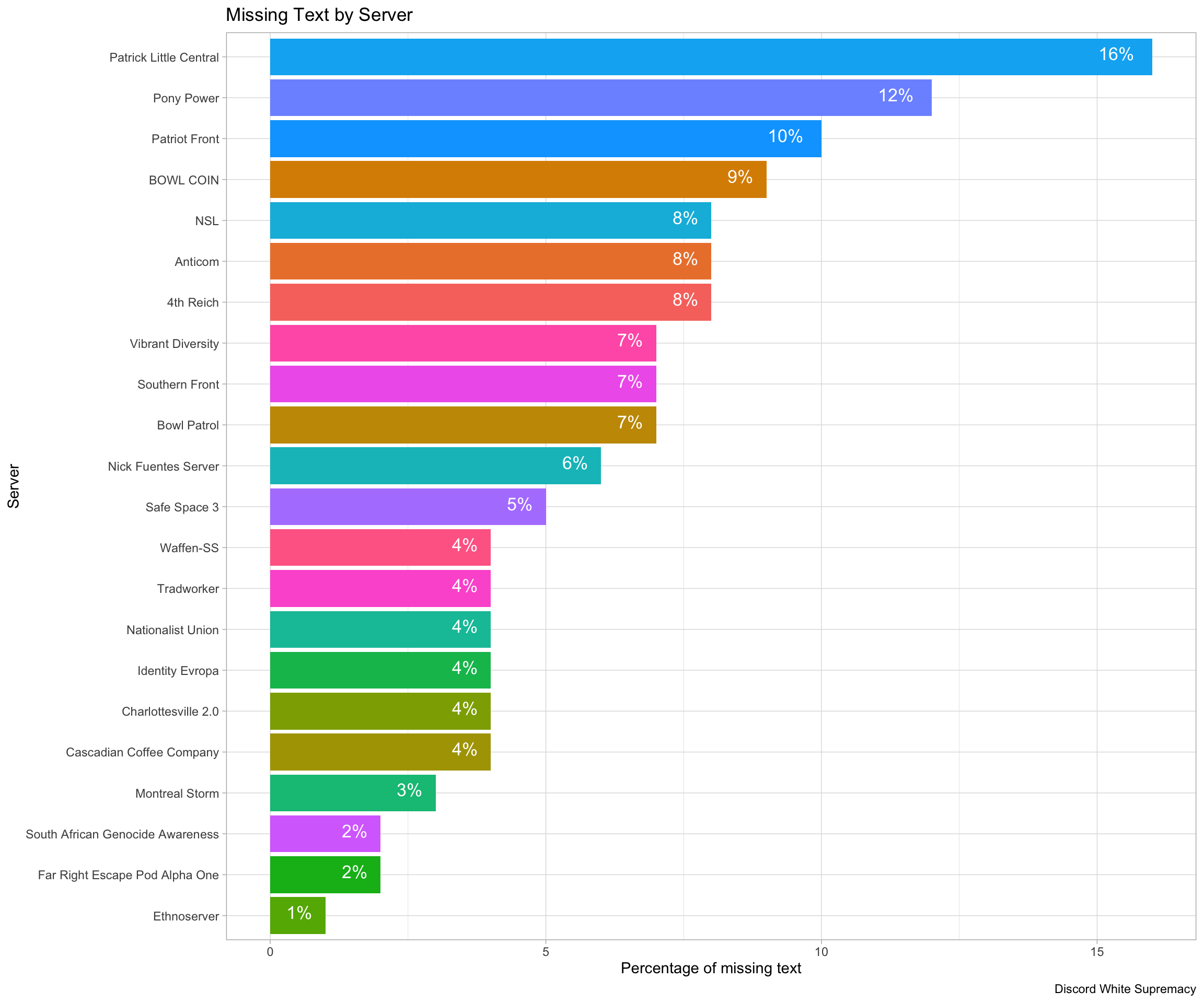
Some servers contain less textual data than others, depending on the amount of images that were shared. Though in total, 6.13% of textual messages were “missing”. Typically, non-text images would include memes or images of activism, all of which was qualitatively coded for. Typically, servers which were less professionalzied posted more images, as they relied on memes quite heavily, whereas meme posting in more activist inclined servers was less accepted.
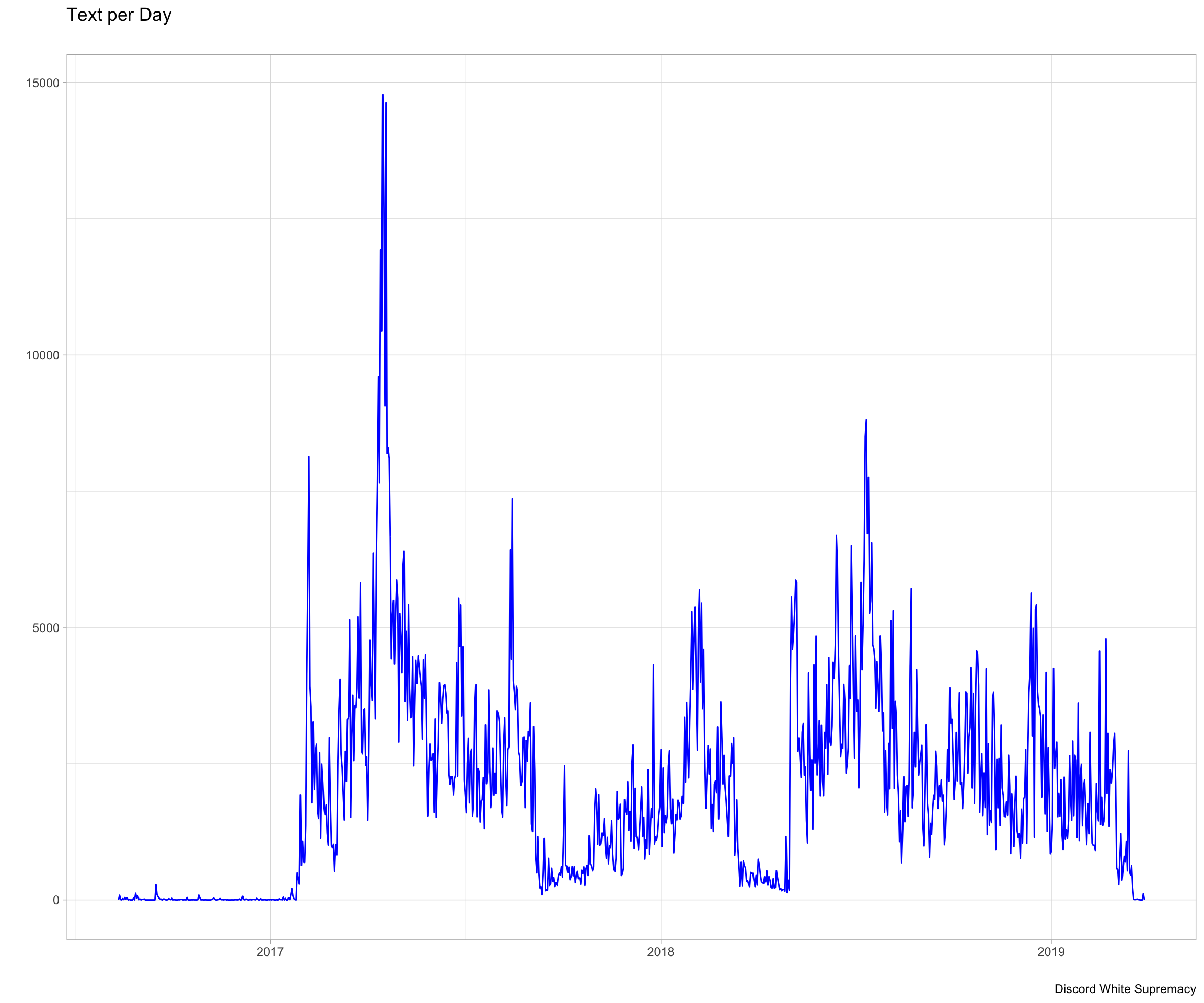
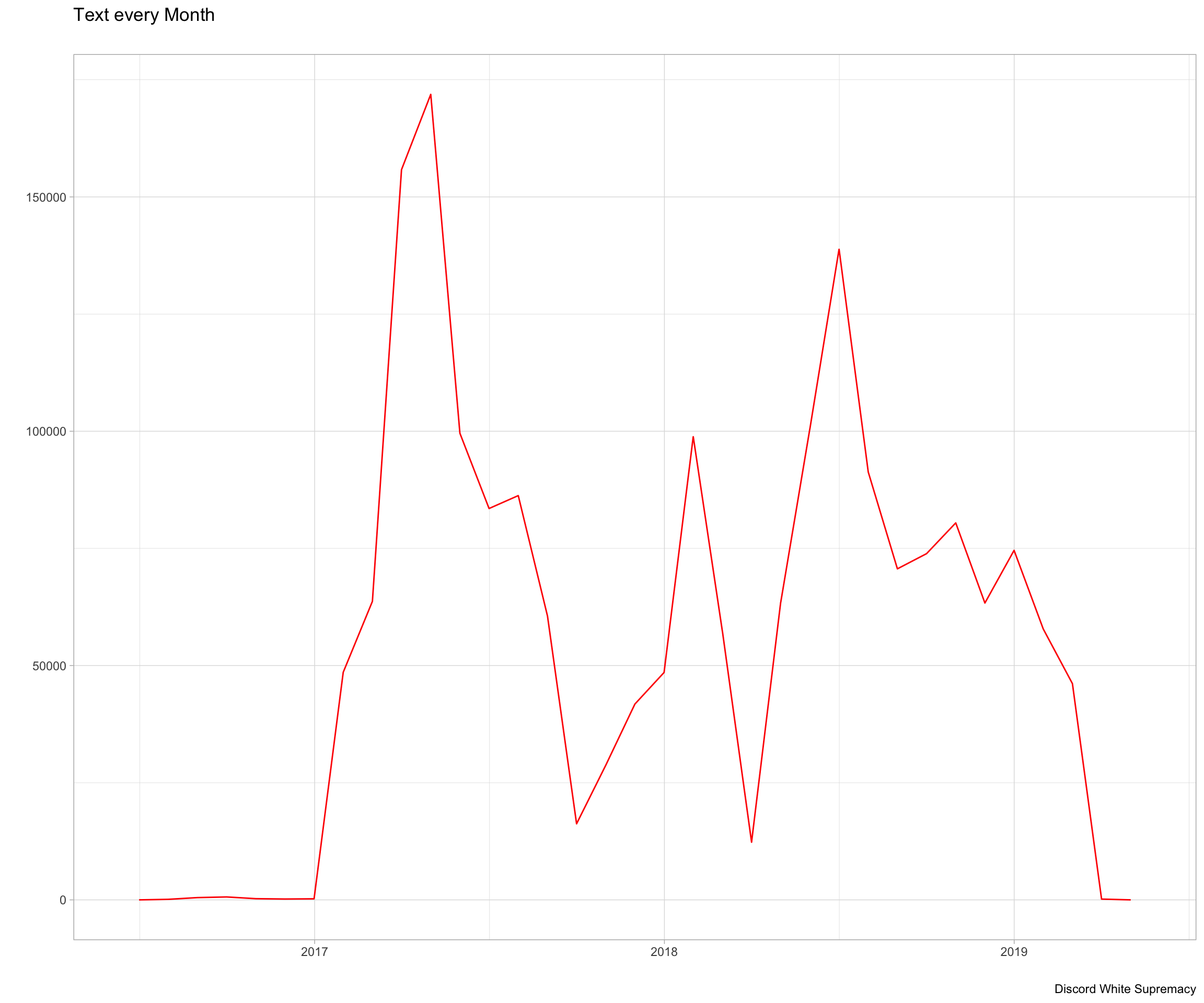
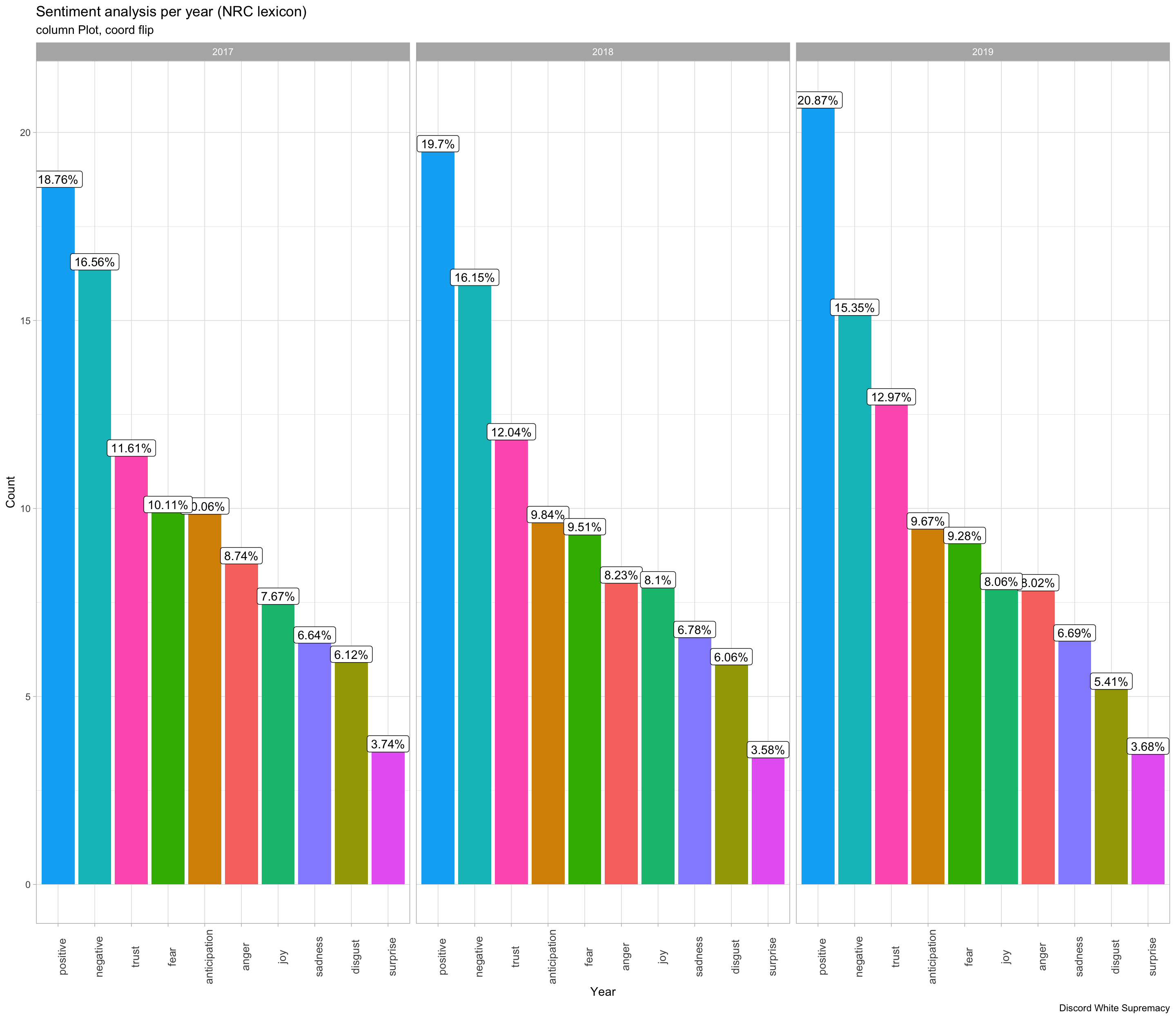
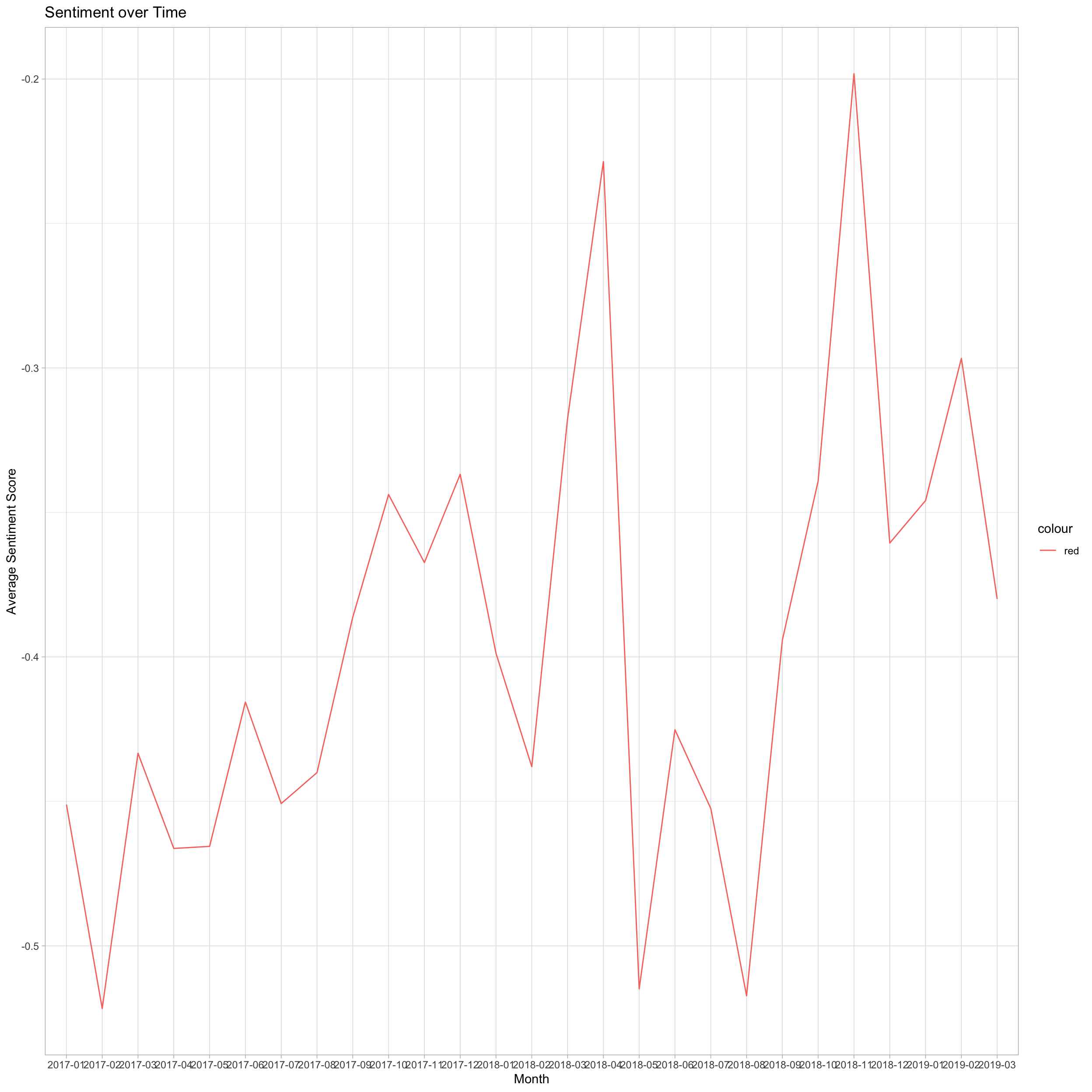
Looking at temporal aspect of the dataset, we see that there was a large spike in messages sent in April of 2017. This corresponds with a large event for the Alt-Right, the 2017 Syria Strikes. These strikes sent the servers into a fury, believing that Trump was finally doing the bidding of his “Zionist puppets”. In 2017, around August-September, we see a large dip in messages corresponding to the first wave of bans by Discord stemming from the fallback of the Unite the Right Rally. Finally the dip in 2019 comes from just after the Christchurch massacre in New Zealand, where Discord once again took a hard approach and banned many far-right organizations, many of which were in my sample.
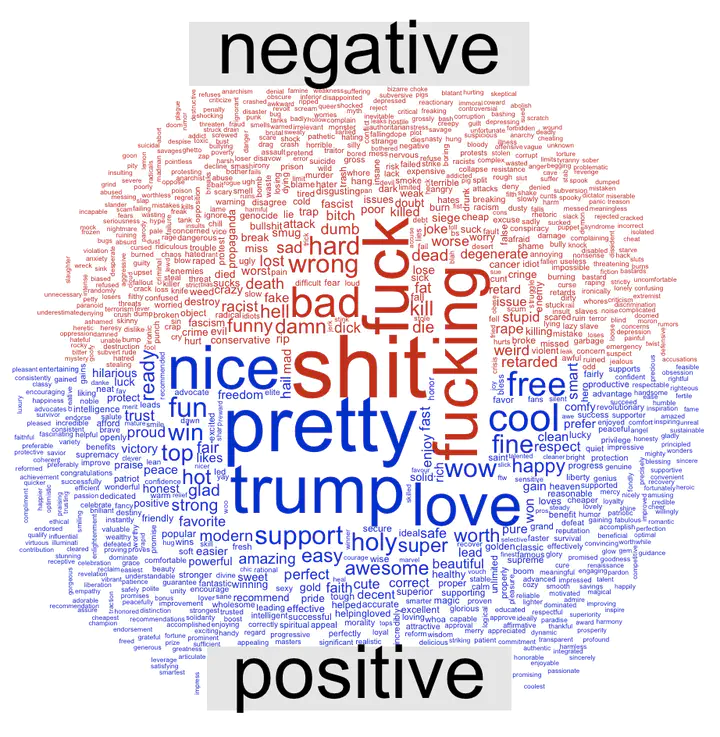
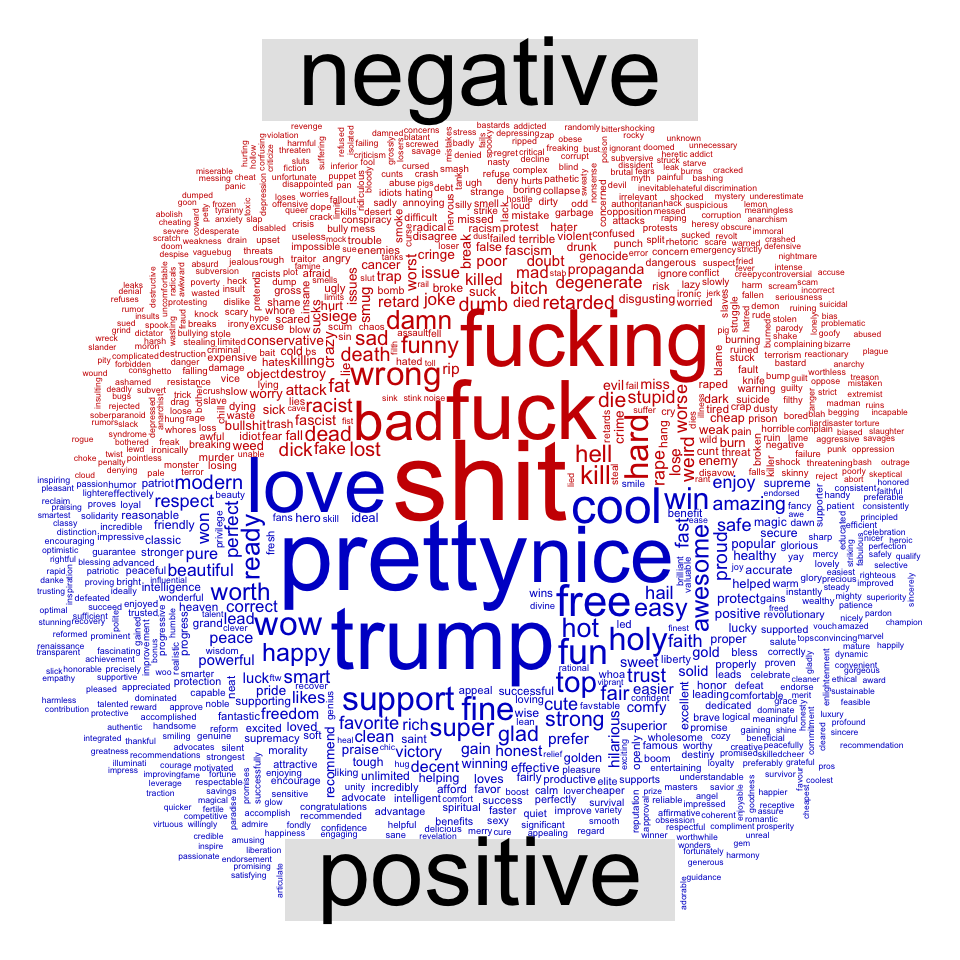
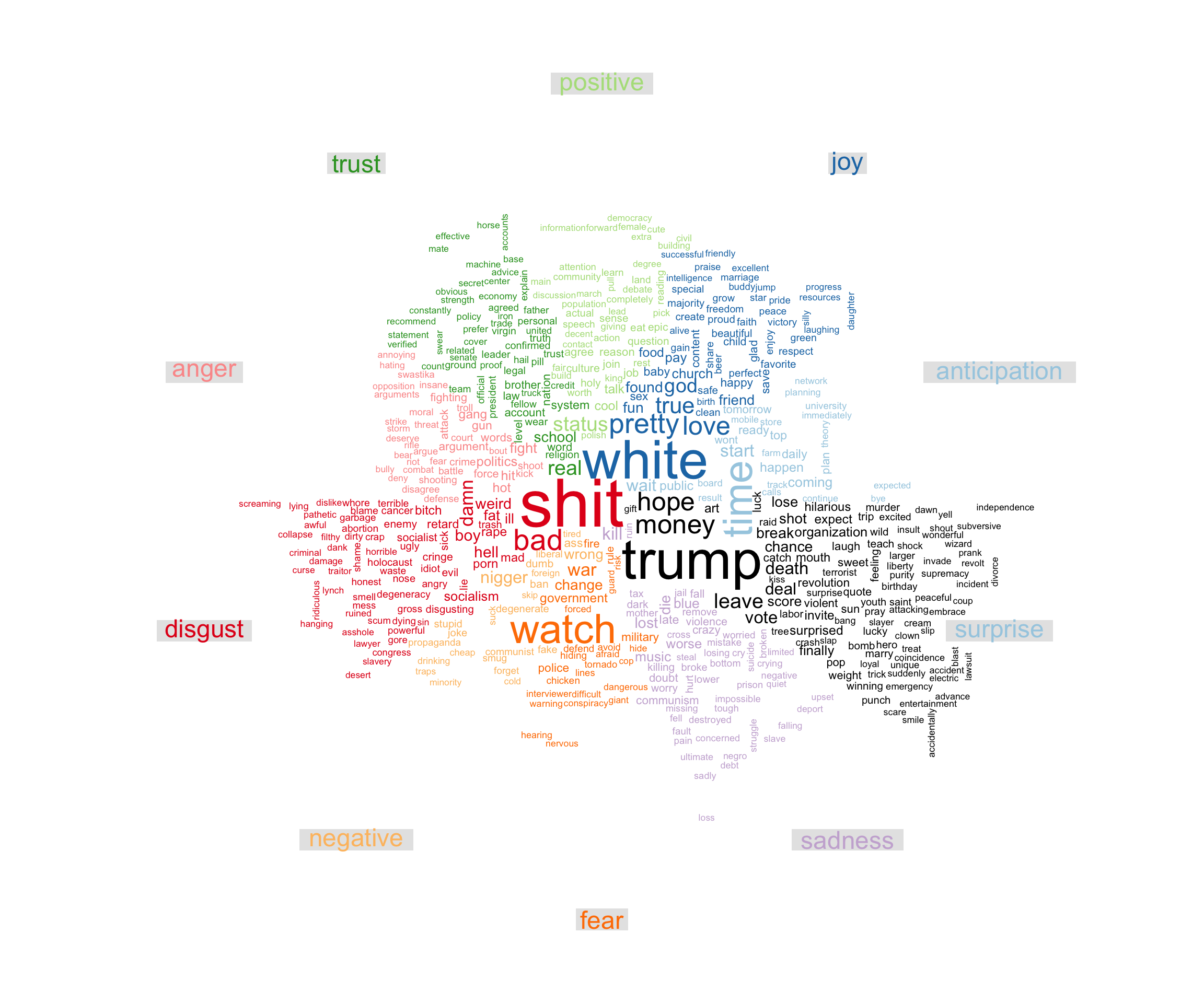
Below is a basic wordcloud using the comparison.cloud() function and the Bing lexicon. I used custom stop_word list which contained several other words such as “Youtube”, “https” and “Discord”, as well as most URLs like “twitter.com”. This was done in order to remove the influence of news links and other common words which were not in the stop_words dataset.
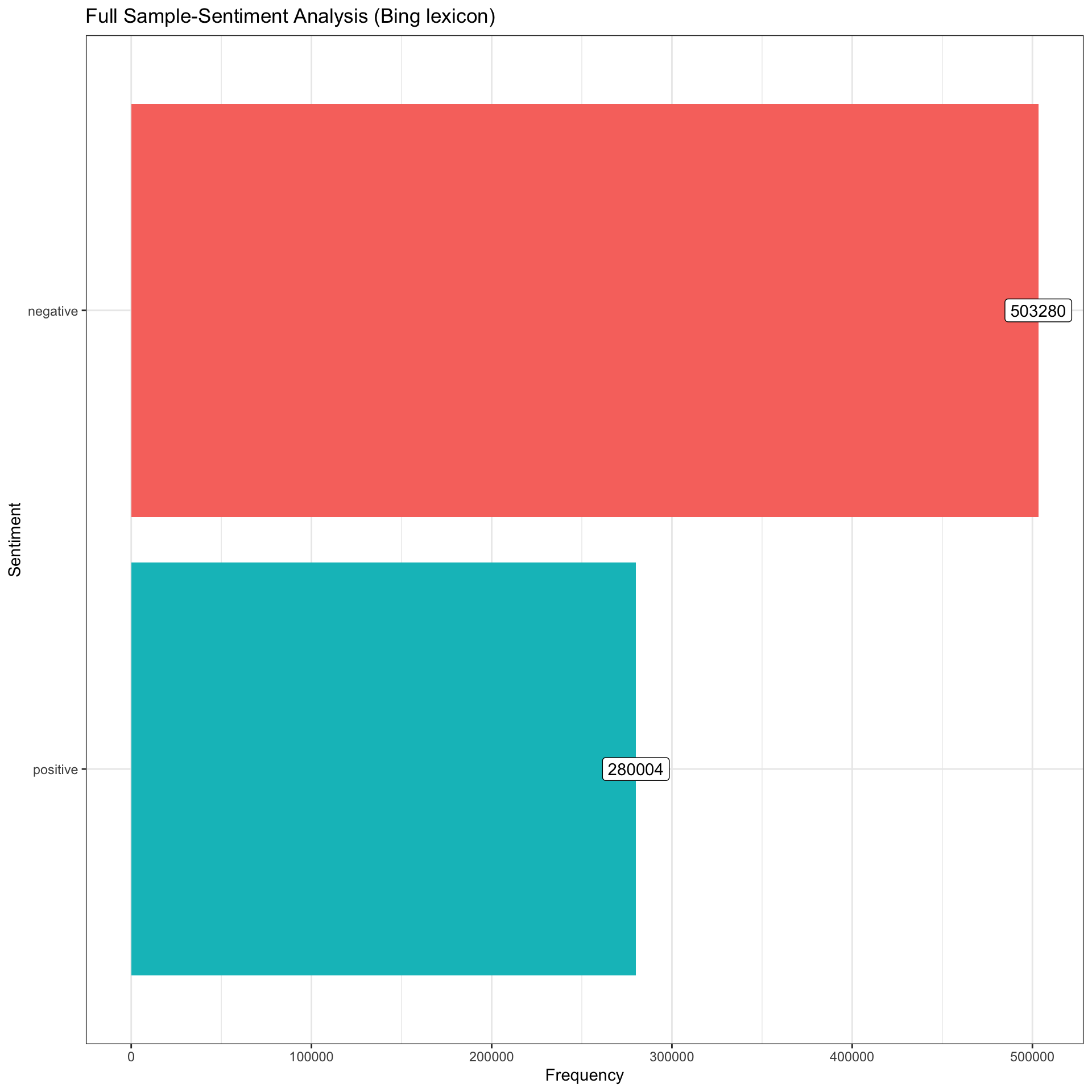
Using the Bing lexicon, we have a total of 515969 “negative” words, 5382479 “neutral” words and 282101 “positive” words, so about 8% are negative, 87% neutral, 4.5% percent positive. Words like “posting” and “brown” are labelled as neutral, but so do words like “shitskins”, a very derogatory term. Even words like “merchant”, which in the dataset are usually used derogatorily to refer to Jewish indviduals is labelled as “neutral”. This is one of the issues with using a generalist stop-word list, as it is not context specific enough to capture the way terms are used. This is an inevitability and an unfortunate common problem when using general stop_word lists. This issue can be corrected for by including new words and giving them a specific “positive” or “negative” value.
Here is a simple visualization of sentiment counts using the Bing lexicon where we can see how much more negative the text is compared to positive. Note that the bing lexicon contains more negative words than positive words in its lexicon (4781 negative words vs. 2005 positive words). Because of this, we can’t tell how negative or poisitive the text data is without a reference point, so below, I compare across servers and other distinguishing factors.
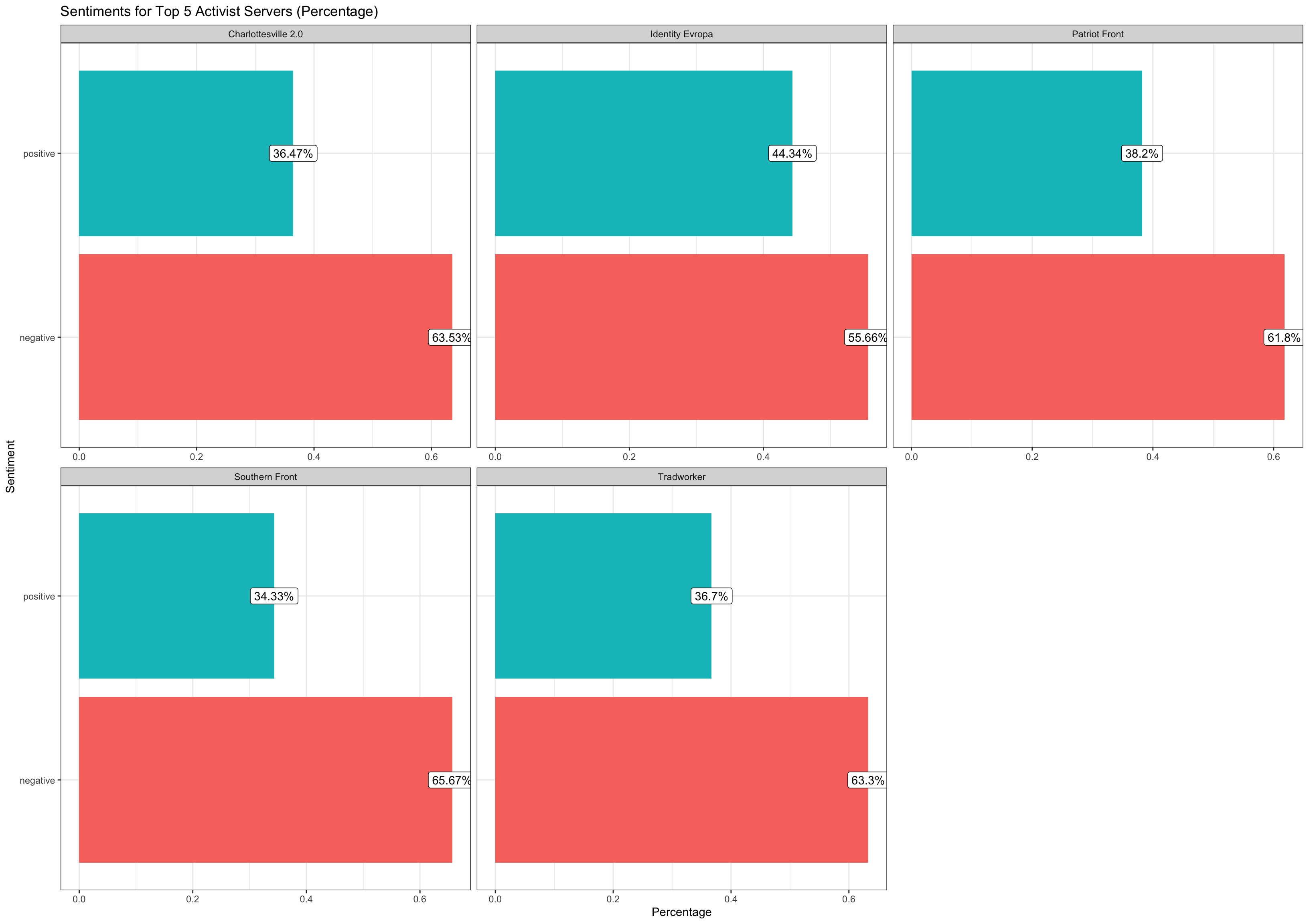
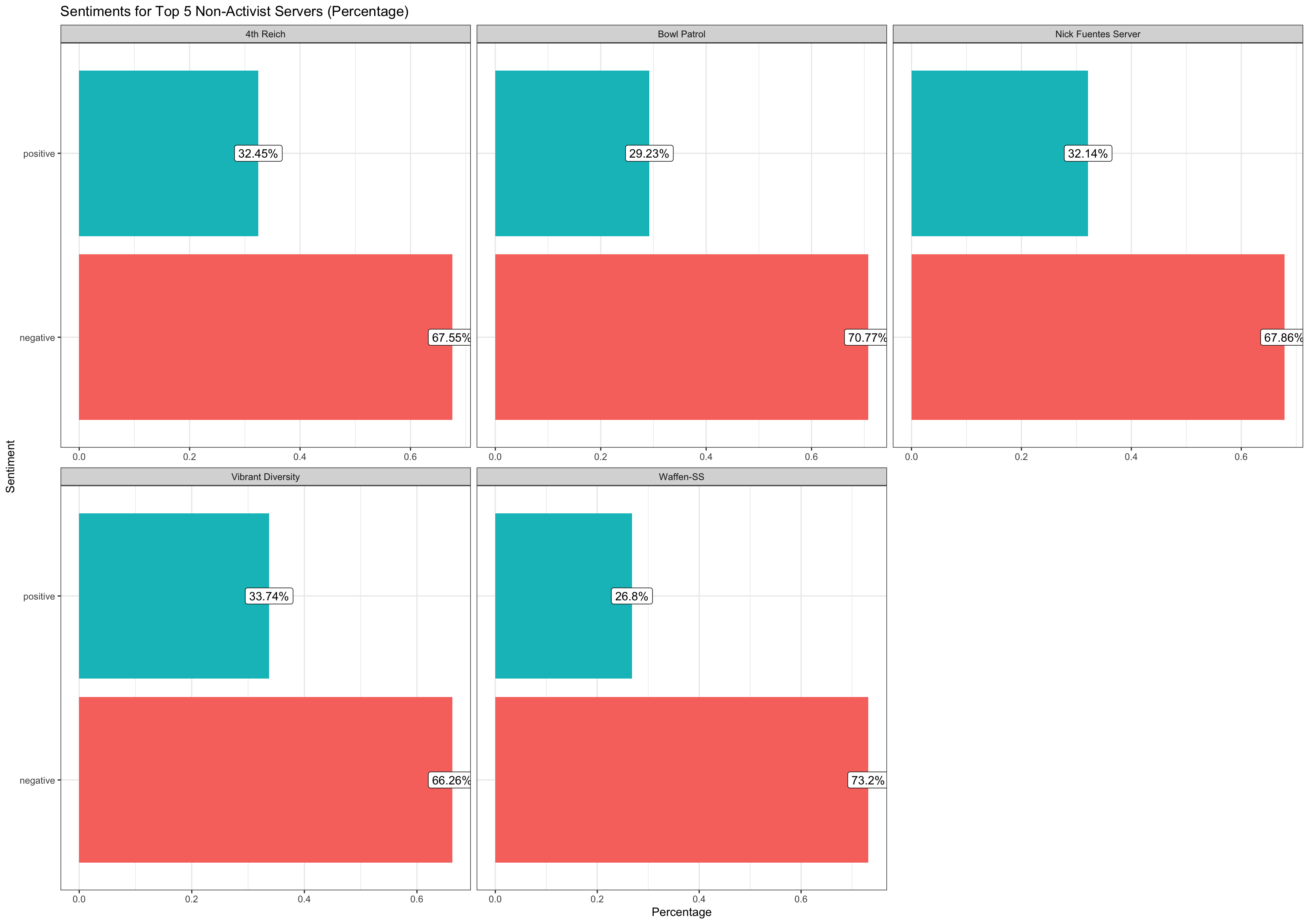
Now here is a comparison between the top 5 activist servers (with a minimum of 50 acts of activism conducted) vs. the top 5 least activist servers. We can see a difference in sentiment across more activism centered servers and those with less activism.
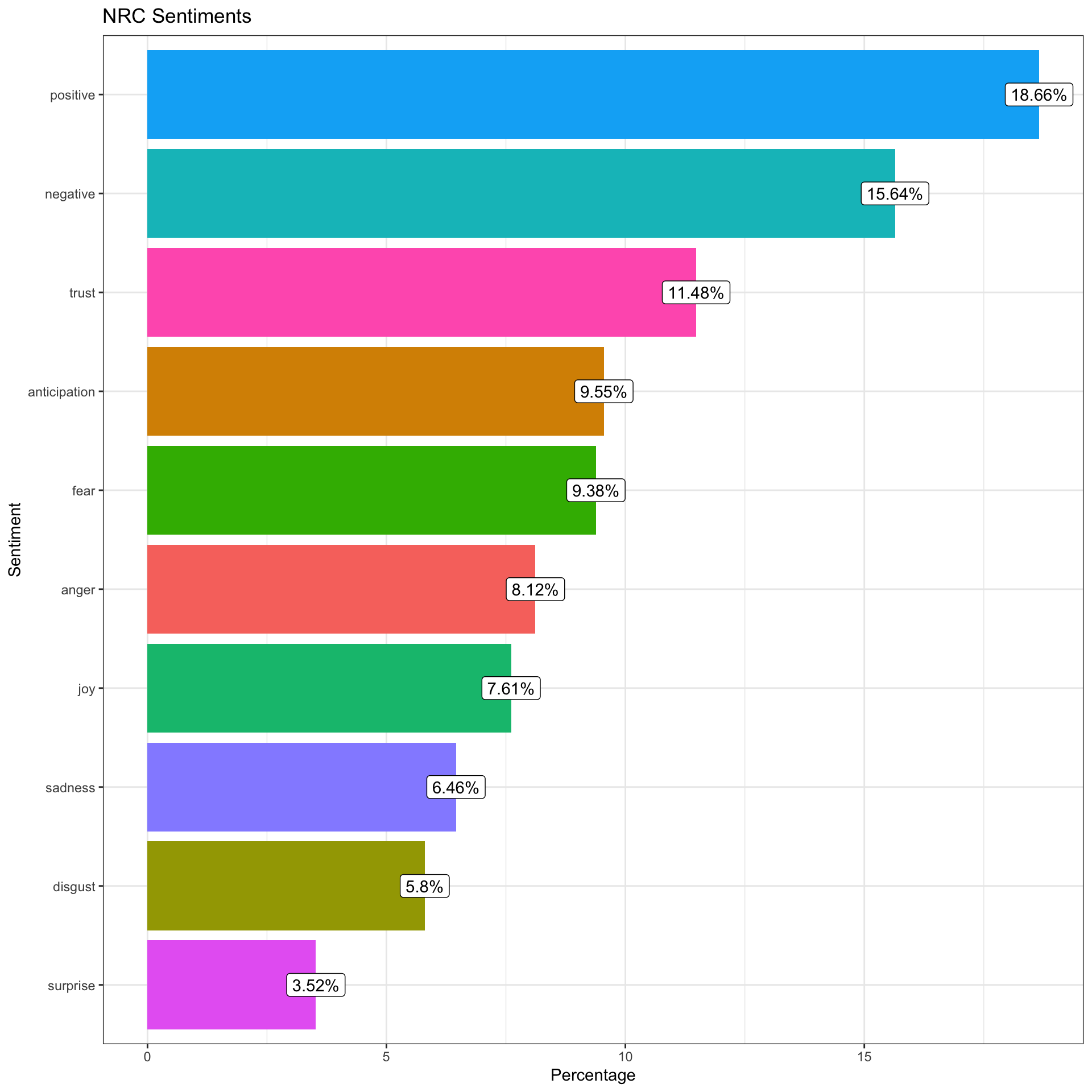
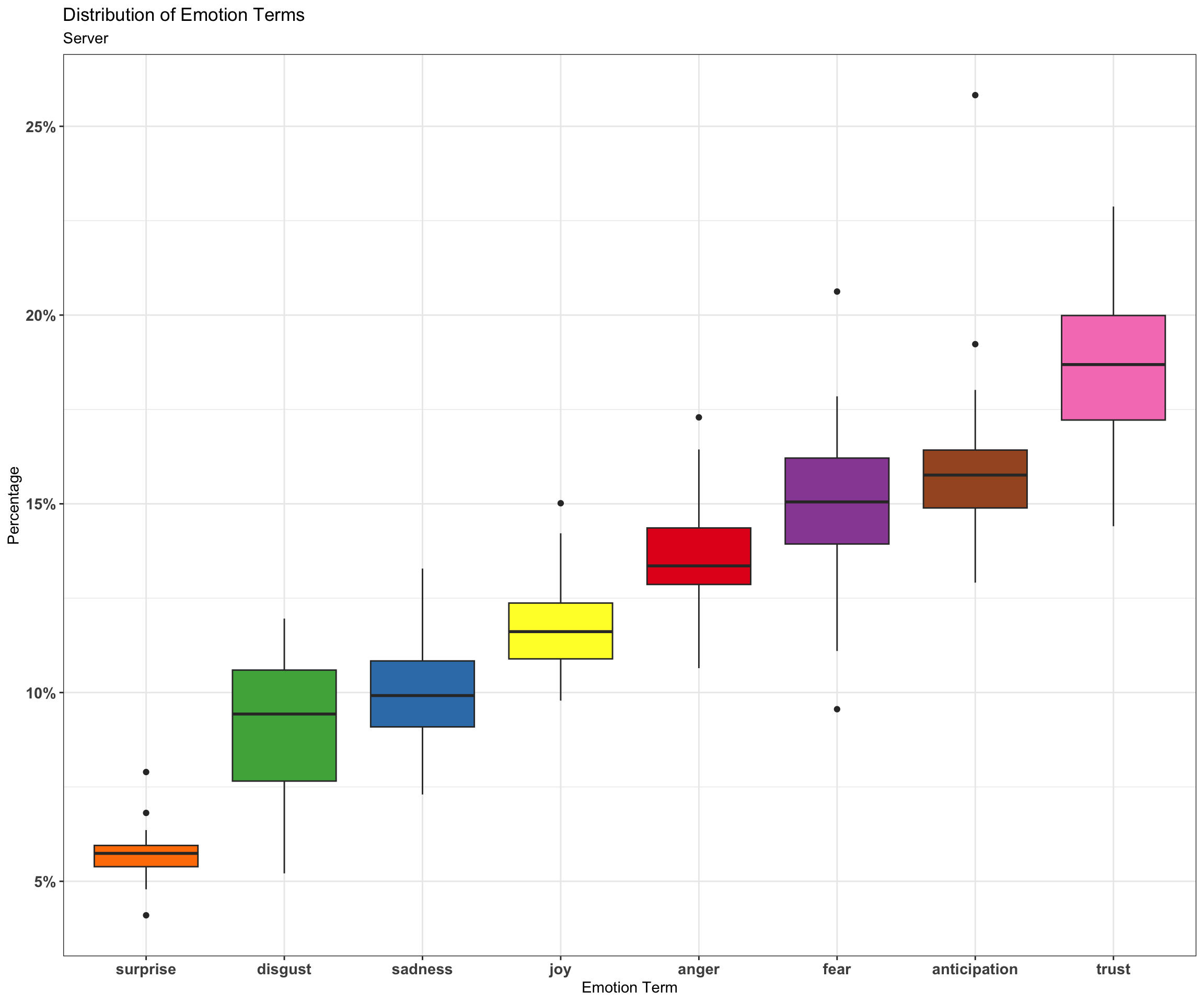
Next we will use the NRC lexicon, which assigns a label to words based on ten different emotion scores: In the NRC lexicon: there are 3324 words that can be categorized as negative along with 2312 positive words.
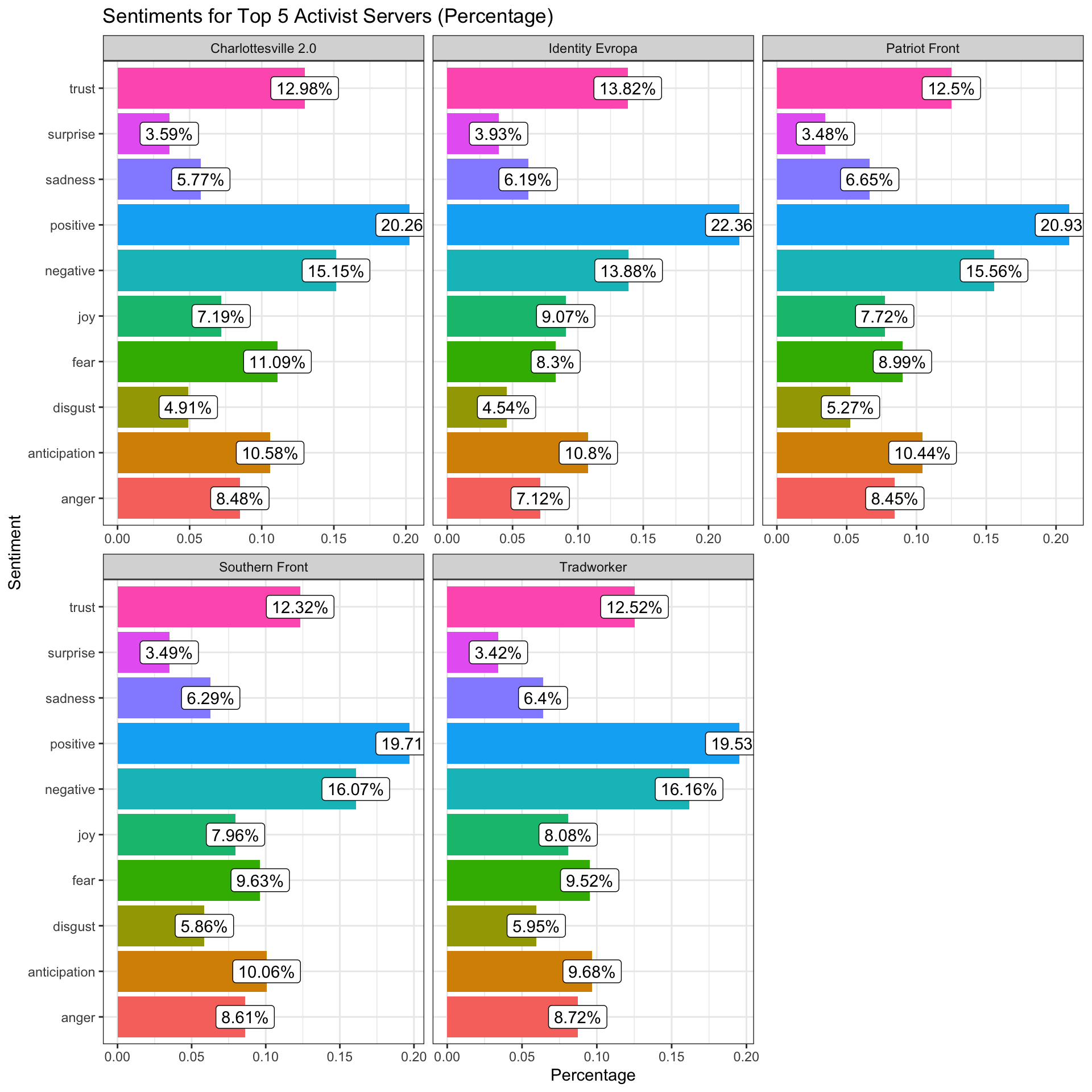
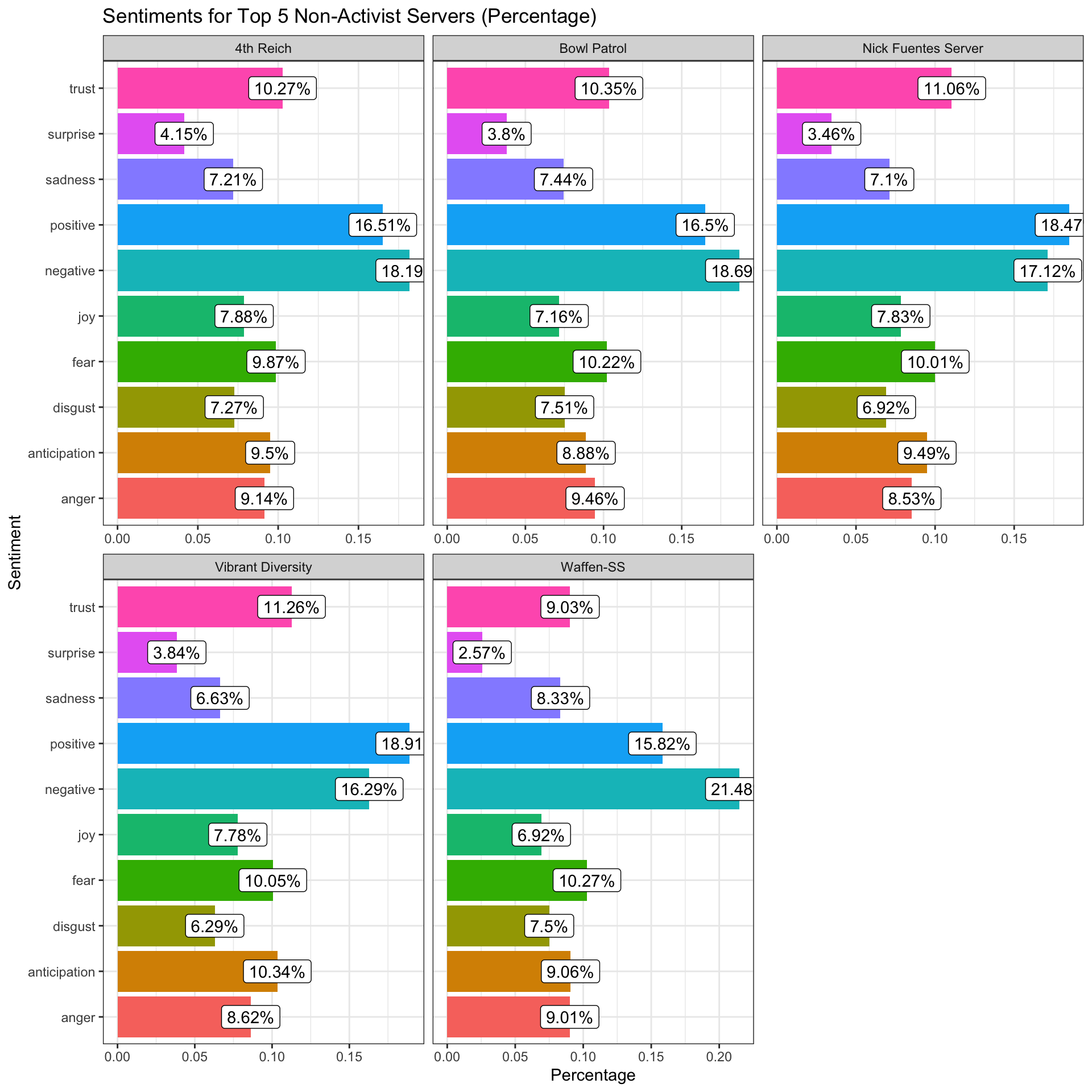
Now here is a comparison between the top 5 activist servers (with a minimum of 50 acts of activism conducted) vs. the top 5 least activist servers using the NRC lexicon
Below is a table showing the total number of tokens from each server:
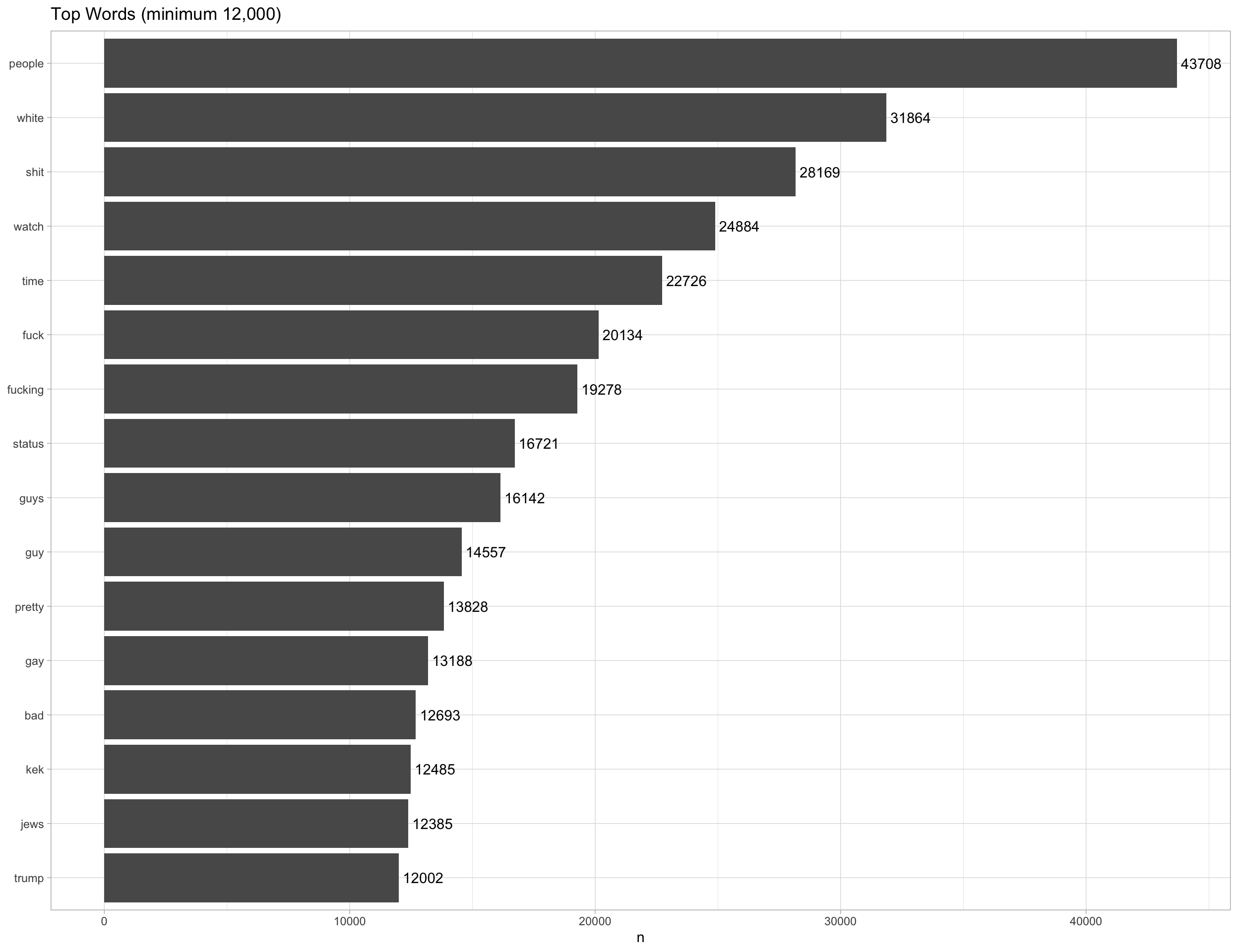
Here we have a graph shpwing the most often used words in the entire dataset (with stopwords, numeric and emojis removed):
Here is a boxplot using the NRC sentiment lexicon:
Alessandro Giuseppe Drago
Post-Doctoral Researcher
My research interests include right wing movements, political sociology and populism